Edit 07/26/2020:
Check out the expanded GIS notes page here!
Using ESRI ArcGIS / ArcMap on Macs: 2 methods
I need to run ESRI products on my MacBook Pro. QGIS is always the prefered solution- open source, excellent free plugins, works on mac natively- but in a college / research environment, the only option that supports other people and school machines is ESRI. Despite the annoying bureaucracy and expense of the software, some things are faster (but not better!) in ESRI, like dealing with raster / multiband data.
First, you need a license.
I went about this two ways;
My first solution was to buy an ESRI Press textbook on amazon. A 180 day trial for $50- when taken as a college course, this isn’t to bad. 🙂 The book is slow and recursive, but a 180 days to play with all the plugins and whistles allows for way deeper learning via the internet. 🙂
Do know there is a little-documented limit to the number of license transfers you may perform before getting either lock in or out of your software. I hit this limit, as I was also figuring out my virtual machine situation, which would occasionally need a re-installation.
My current solution is “just buy a student license”. $100 per year is less than any adobe situation- so really not that bad.
Now you need a windows ISO.
https://www.microsoft.com/en-us/software-download/windows10ISO
Follow that link for the window 10, 64 bit ISO. YOU DO NOT NEED TO BUY WINDOWS. It will sometimes complain about not having an authentication, but in the months of using windows via VMs, never have I been prohibited to do… anything. When prompted for a license when configuring your VM, click the button that says "I don’t have a license". Done.
Option one: VirtualBox VM on a thumbdrive
https://www.virtualbox.org/wiki/Downloads – download for the VM software
http://a.co/4FEYMNY, http://a.co/hanHYl1 Suitable USBs. the VM will take up most of a 128gb flash drive- ~70 gb just for windows and all the stuff you’ll want from a PC. Add ESRI software and allocated space for a cache (where your GIS project works!), bigger is better. Format all drives in disk utility as ExFat! this is important, any other file system either won’t fly or could wreak havoc (other FAT based ones may have too small file allocations!
I used two drives, a 128 and a 64- this is great because I can store all my work on the 64, so I can easily plug it into other (school) machines running windows ArcMap and keep going, without causing issues with the massive VM in the 128.
Installation is straightforward, just install EVERYTHING on the usb drive and it will be fine. 🙂


Problems: Stability. Crashes, and python / some other script modules do not work well. This is a problem. ArcAdministrator gets confused about all kinds of things- FWIW, if you are googling to delete the FLEXnet folder to solve authentication file issues, move to option 2 🙂
Speed is down, but actually the ~same speed as our school "super" PCs- (though I happened to know they are essentially glorified "hybrid" VMs too!) .

Option two: OSX Bootcamp
https://support.apple.com/boot-camp
https://support.apple.com/en-us/HT201468
This way, you will hit "option/alt" each time you restart/boot your computer to choose from win/osx. This is easy to install, as it is mac and mac = easy.
Big Caveat: it is much harder to install windows externally (on a usb, etc) from bootcamp. I didn’t succeed in my efforts, but there could be a way…. The thing is, it really wants to run everything like a normal intel based PC, with all installations in the usual place. This is good for the mac performance, but terrible for the tiny SSD hard drives we get as mac users. I have a 256gb SSD. I have an average of < 15 gb wiggle room here, and use every cloud service in the book.
If you need to manage your cloud storage because of a itsy mac SSD, my solution is still ODrive. https://www.odrive.com/
I use Amazon cloud mostly with odrive, but I use a personal/school OneDrives, Dropboxes, Google, etc. with only the occasional hiccup. Also, all of the AWS tools are great and cheap- EC2, S3, Cloud 9, lambda, RDS…. Great way to do your work outside of your mac via the internet.
Result:
ArcMap and GIS stuff is blazing fast on my modest 2015 i5/8gb macbook pro. Comparing a huge, mega ATX+ school computer to my mac on boot camp, I am running large raster filtering operations significantly quicker than other folks doing the same type of work. That is GOOD.
🙂
-Jess
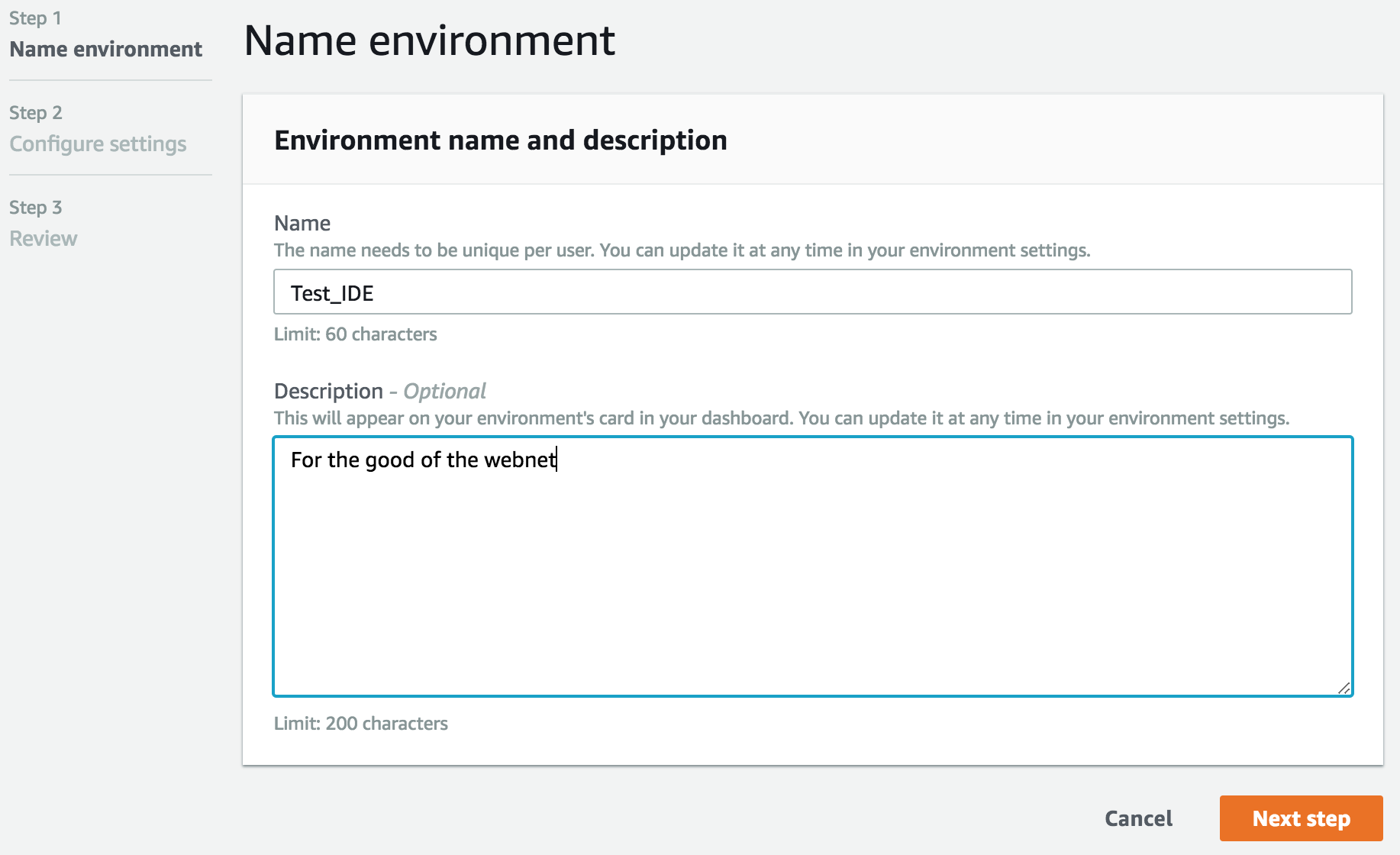 Open the cloud 9 tab under services.
Open the cloud 9 tab under services. Know this ideally a browser-based service; I have tried to come up with a reason a SSH connection would be better and didn’t get any where.
Know this ideally a browser-based service; I have tried to come up with a reason a SSH connection would be better and didn’t get any where. The default network settings are set up for you. This follows good practice for one person; more than that (or if you are perhaps a far-travelling person) note these settings. They are always editable under the VPC and EC2 instance tabs.
The default network settings are set up for you. This follows good practice for one person; more than that (or if you are perhaps a far-travelling person) note these settings. They are always editable under the VPC and EC2 instance tabs.










 This tool allows us to find and track birds and their friends (such as “migrant warblers”) around the world. This is a great way to get a handle on migrations, local
This tool allows us to find and track birds and their friends (such as “migrant warblers”) around the world. This is a great way to get a handle on migrations, local  (owls are great!) and other species that can otherwise “fly under your radar”.
(owls are great!) and other species that can otherwise “fly under your radar”.





















































































